
The Hebrew alphabet supports a limited character set of 27 symbols. Five letters have a final form that gets used when the character appears at the end of a word (“sofit”).
Hebrew has block letters. Don’t look for case differences: HEBREW HAS NO LOWERCASE OR UPPERCASE LETTERS – JUST “PRINT” LETTERS!
The symbol set is an “abjad”, a writing system composed of consonants. The vowels are not usually written (except in the Bible, poetry and books for children and foreign learners) but inferred. (The reader must know how each word is pronounced.) THR R N LWRCS R PPRCS LTTRS N HBRW!
Hebrew is written from right to left, just like Arabic. (Let’s face it: Hebrew is not the easiest language to read...) !WRBH N SRTTL SCRPP R SCRWL N R RHT
However, Hebrew does not have any separate numerals. The standard Western and Roman numerals (1, 2, 3 etc.) are used instead. Furthermore, these numbers are written from left to right, and so are embedded phrases in Latin script. In other words: when numbers and Latin words are inserted in Hebrew texts, both the reading direction and the alphabet change in mid course.
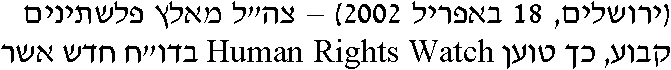
And that’s not the only challenge when you develop an OCR engine for Hebrew. Here’s another particular element you don’t find in the other (Latin, Greek, Cyrillic and Arabic) alphabets: Hebrew text is not written on lines. Rather the text hangs from a line above the letters! (In technical terms: the “base line” is above the characters, not under it!)

Which languages can OCR software read? — The history of the alphabets – Latin alphabet — Latin punctuation — Greek alphabet — Cyrillic (Russian) alphabet — Hebrew alphabet — Arabic alphabet — Let’s go East – Chinese alphabet — Japanese alphabet — Korean alphabet — Asian punctuation
Home page — Intro — Scanners — Images — History — OCR — Languages — Accuracy — Output — BCR — Pen scanners — Sitemap — Search — Contact – Feedback
